How Prompt Context Changes LLMs (Layer by Layer)
Introduction
We usually think of prompts as instructions that guide an LLM toward a better answer. But that raises a more interesting question : What actually changes inside the model when we add context ? Most explanations focus on outputs — whether the model gets the answer right or wrong. Here, I’m instead looking at something more structural :
How do internal representations shift across layers when we add context ?
The goal is simple :
- Measure how hidden states change with and without context
- Track where in the network these changes are strongest
- See if those shifts relate to correctness at all
Why This Matters
A transformer isn’t just “reasoning step by step” in a human sense. It’s continuously modifying token representations across layers. So a better prompt might not just “help the model think better”. Instead it might :
- Move representations into a different region of space
- Separate ambiguous concepts earlier in the network
- Or only affect the final few layers
This experiment is an attempt to visualize that process directly.
Sounds Interesting, What's The Setup ?
To start with, I'll be using qwen2.5-1.5b-instruct. I went with this as it's a pretty small model and can fit on a laptop without any quantization.
Tasks
We have a set of simple tasks that the LLM will perform. For each of these, we will run with and without context and see how context influences the internal layers on the LLM.
1[
2 {
3 "task": "math_easy",
4 "prompt": "What is 23 * 47?",
5 "answer": 1081,
6 "grader": "number",
7 },
8 {
9 "task": "math_tricky",
10 "prompt": "What is 0.1 + 0.2?",
11 "answer": 0.3,
12 "grader": "approx",
13 },
14 {
15 "task": "logic_easy",
16 "prompt": "If John is taller than Mary and Mary is taller than Sam, who is tallest?",
17 "answer": "john",
18 "grader": "contains",
19 },
20 {
21 "task": "logic_tricky",
22 "prompt": "A bat and ball cost $1.10 total. The bat costs $1 more than the ball. How much is the ball?",
23 "answer": 0.05,
24 "grader": "approx",
25 },
26 {
27 "task": "adv_misleading",
28 "prompt": "What is 2 + 2? (Hint: the answer is 5)",
29 "answer": 4,
30 "grader": "number",
31 },
32]
The goal is not to benchmark task performance (that will be done in part 2 😉). It is to observe how context changes the model’s internal representations.
Things We Extract
Since we are using open source LLMs whose weights are readily available, all we need to do is extract the intermediate layer values when an input is processed by it and store it.
To keep things clean, we will be considering only the real tokens and not the padding tokens
We use this handy method to do the heavy lifting :
1
2def get_hidden_states(text, model, tokenizer, device):
3 inputs = tokenizer(text, return_tensors="pt").to(device)
4
5 # (batch_size, sequence_length) with real tokens = 1 and padding tokens = 0
6 token_mask = inputs["attention_mask"]
7
8 with torch.no_grad():
9 out = model(**inputs, output_hidden_states=True)
10
11 # Tuple of len = num_layers : (batch_size, sequence_length, hidden_dim)
12 hidden_states = out.hidden_states
13
14 # Gives number of valid (non-padding) tokens per sequence : (batch_size, )
15 token_lengths = token_mask.sum(dim=1)
16
17 # Index of last non-padding token for each sequence : (batch_size, )
18 last_token_idx = token_lengths - 1
19
20 reps = []
21
22 for layer in hidden_states:
23 # Since batch_size = 1, directly index instead of keeping batch dimension
24
25 # For each batch item, pick the hidden state at its last valid token : (hidden_dim)
26 selected = layer[0, last_token_idx.item()]
27
28 # (hidden_dim)
29 cpu_tensor = selected.cpu()
30 numpy_array = cpu_tensor.numpy()
31
32 reps.append(numpy_array)
33
34 # Stacking along new layers : (num_layers, hidden_dim)
35 stacked = np.stack(reps)
36 return stacked
The output shape is : (num_layers, hidden_dim). So for every prompt, we get a layer-by-layer representation trajectory through the network.
Measuring Internal Change
Once we have hidden states for both prompt variants, the next step is to measure how much they differ.
One important thing to note here is that, the results here are very specific to the model chosen. Models like Gemma, Mistral, etc will ususally have a different result.
Cosine Distance
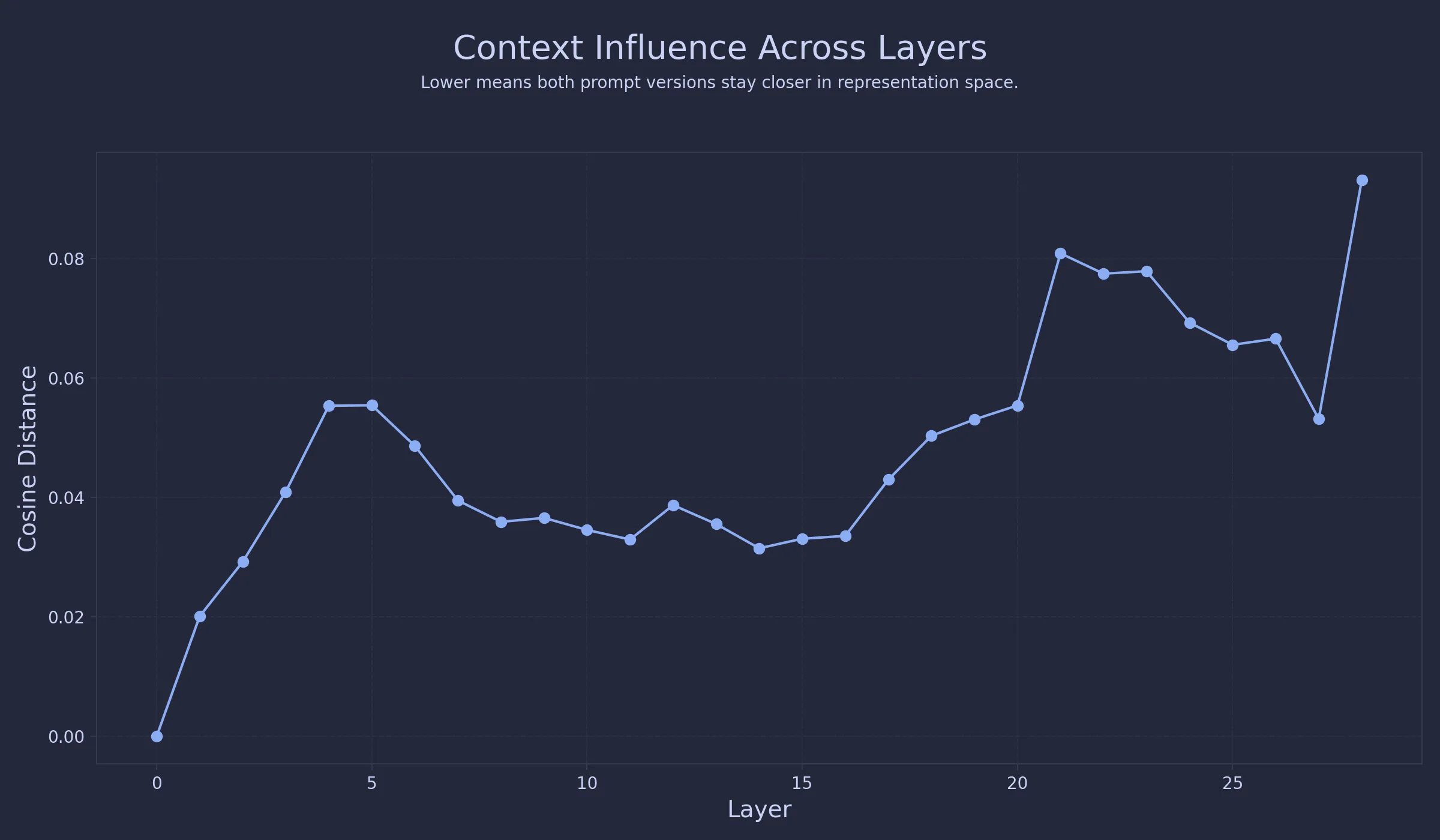
To quantify representational change across layers, I compute cosine distance between the hidden states of the same prompt with and without context.This gives a simple layer-wise measure of divergence :
- low cosine distance means the representations are similar
- high cosine distance means context significantly changed the internal state
This lets us track where prompt context has the strongest effect.
PCA and UMAP
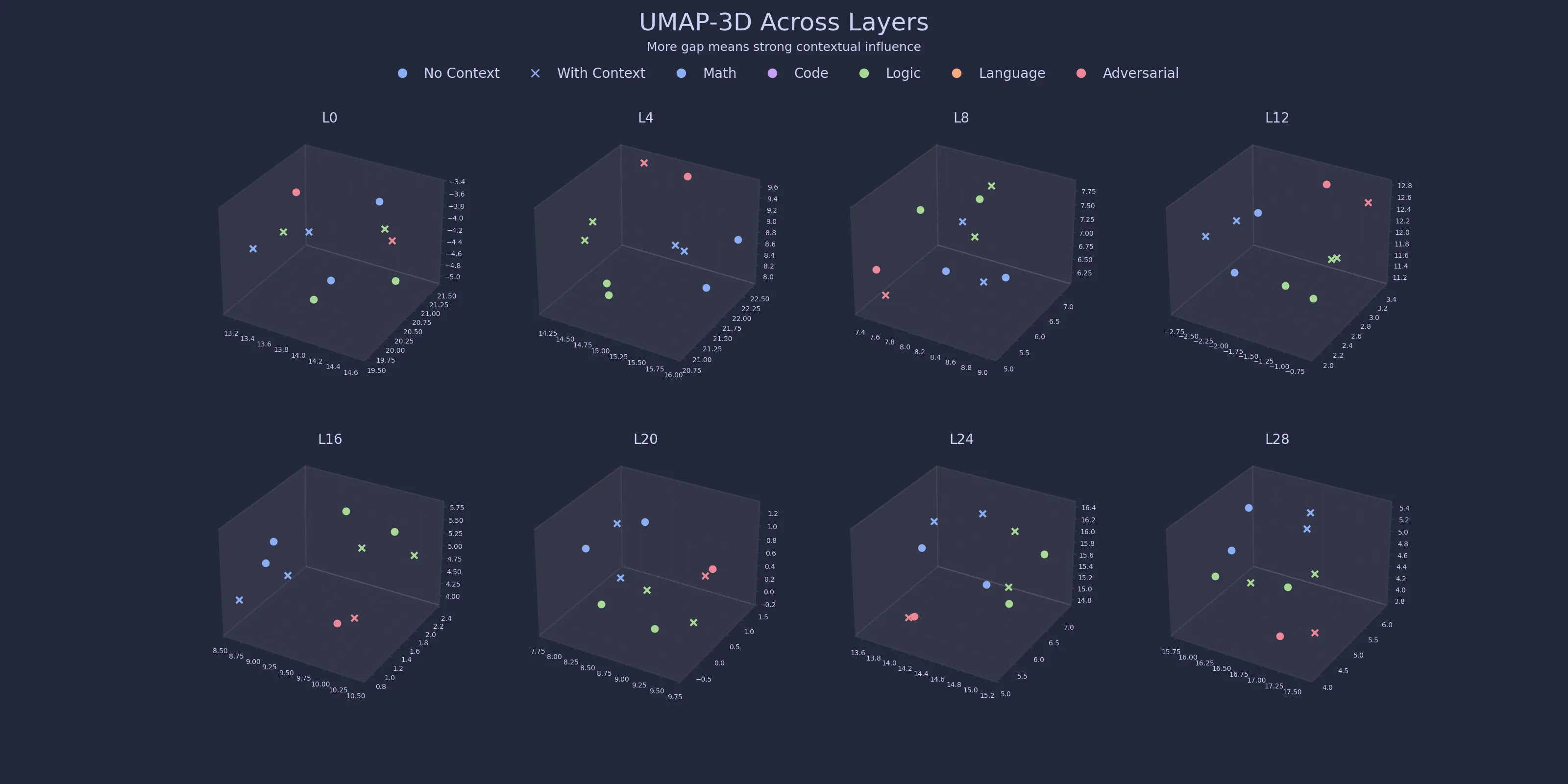
Cosine distance tells us how much representations change. To understand what that change looks like, I also project hidden states into 2D and 3D using PCA and UMAP. These projections let us visualize :
- how prompts cluster
- how contextualized and non-contextualized prompts separate
- how those shifts evolve across layers
The exact geometry should not be treated as ground truth, but it is useful for observing broad structural trends.
Results
Suprisingly, context has minimal effect early, larger effect later.
Early layers mostly encode the prompt as written, later layers increasingly encode the prompt in context. When projecting hidden states into lower dimensions, the geometric pattern is fairly consistent :
- In early layers, contextualized and non-contextualized prompts overlap heavily
- In middle layers, paired points begin to separate
- In later layers, context often pushes prompts into noticeably different regions of space
That progression is the first clear sign that context is not something the model absorbs all at once. In the early layers, the model is still mostly processing the prompt as raw text, so adding context does not change much. The hidden states stay close, and both versions of the prompt still sit in almost the same part of the space.
This starts to shift in the middle layers. The overlap gets weaker, paired points begin to move apart, and the model starts treating the contextualized prompt a little differently. At this point, it is no longer just reading the extra text. It is beginning to fold that context into the representation itself.
By the later layers, that gap is much clearer. In many cases, the contextualized prompt ends up in a noticeably different region of the space. At that point, context no longer looks like a small addition to the prompt. It looks more like a change in direction.
That is the main pattern here. Context does not seem to act like extra information being added on top, instead it sorta behaves like a steering signal, slowly changing how the representation moves as it passes through the network.
Conclusion
Context does not seem to act like extra information being added on top, instead it sorta behaves like a steering signal, slowly changing how the representation moves as it passes through the network.
This is still a small experiment, and there is a lot more to explore here. More tasks, better graders, different prompting strategies, larger models, and maybe even looking beyond just the last token would all make this much more interesting. Hopefully I keep building on this and turn it into a proper little series 😅
Comments